
SpiderLing
SpiderLing — a web spider for linguistics — is software for obtaining text from the web useful for building text corpora.
Many documents on the web only contain material not suitable for text corpora, such as site navigation, lists of links, lists of products, and other kind of text not comprised of full sentences. In fact such pages represent the vast majority of the web. Therefore, by doing unrestricted web crawls, we typically download a lot of data which gets filtered out during post-processing. This makes the process of web corpus collection inefficient.
The aim of our work is to focus the crawling on the text rich parts of the web and maximize the number of words in the final corpus per downloaded megabyte. Nevertheless the crawler can be configured to ignore the yield rate of web domains and download from low yield sites too.
Paper | Cite | LicenceGet SpiderLing
Download the latest version of SpiderLing. Please note the software is distributed as is, without a guaranteed support.
Publications
Chapter 1 in Vít Suchomel's Ph.D. thesis (defended in 2020):
Better Web Corpora For Corpus Linguistics And NLP
We also presented our results at the following venues:
Efficient Web Crawling for Large Text Corpora
by Jan Pomikálek, Vít Suchomel
at ACL SIGWAC Web as Corpus (at conference WWW), Lyon, April 2012
Large Corpora for Turkic Languages and Unsupervised Morphological Analysis
by Vít Baisa, Vít Suchomel
at Language Resources and Technologies for Turkic Languages (at conference LREC), Istanbul, May 2012
The TenTen Corpus Family
by Miloš Jakubíček, Adam Kilgarriff, Vojtěch Kovář, Pavel Rychlý, Vít Suchomel
at 7th International Corpus Linguistics Conference, Lancaster, July 2013.
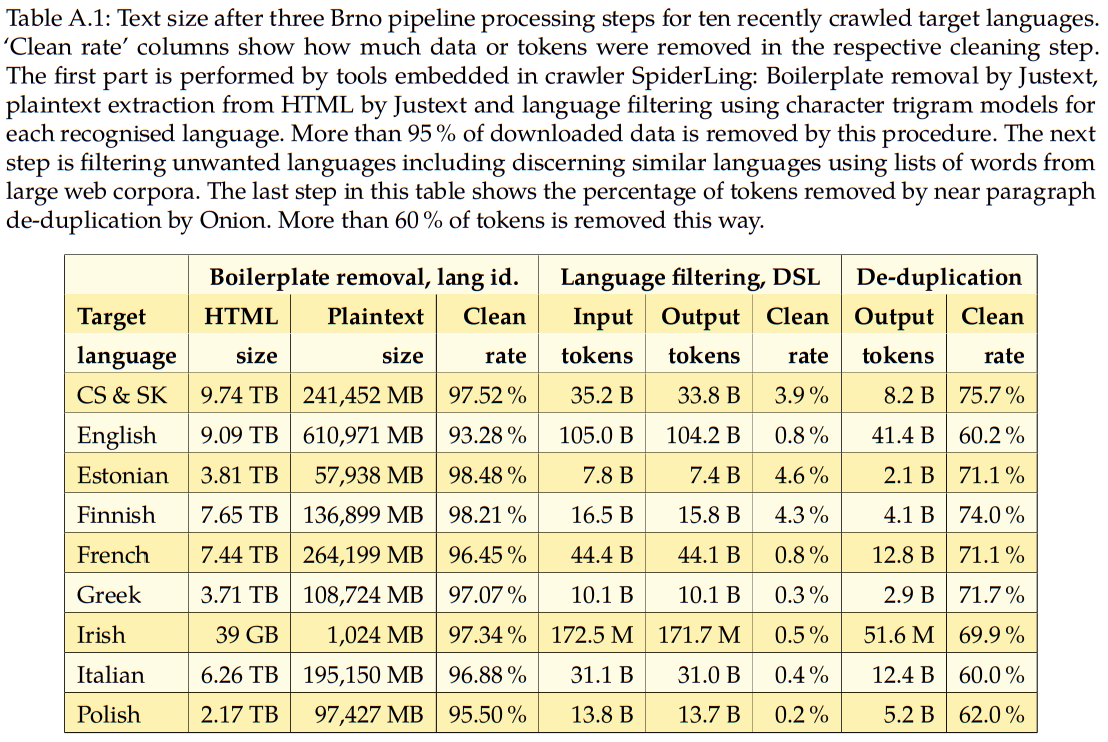
Large textual corpora built using SpiderLing
From 2017 to 2020
Corpora of total size of ca. 200 billion tokens in various languages (mostly English) were built from data crawled by SpiderLing from 2017 to March 2020.

Table source: Page 128 of Suchomel, Vít. "Better Web Corpora For Corpus Linguistics And NLP." Dissertation thesis, Masaryk university, 2020.
From 2011 to 2014
| language | raw data size [GB] | cleaned data size [GB] | yield rate | corpus size [billion tokens] | crawling duration [days] |
|---|---|---|---|---|---|
| American Spanish | 1874 | 44 | 2.36% | 8.7 | 14 |
| Arabic | 2015 | 58 | 2.89% | 6.6 | 14 |
| Bulgarian | 0.9 | 8 | |||
| Czech | ~4000 | 5.8 | ~40 | ||
| English | 2859 | 108 | 3.78% | 17.8 | 17 |
| Estonian | 100 | 3 | 2.67% | 0.3 | 14 |
| French | 3273 | 72 | 2.19% | 12.4 | 15 |
| German | 5554 | 145 | 2.61% | 19.7 | 30 |
| Hungarian | 3.1 | 20 | |||
| Japanese | 2806 | 61 | 2.19% | 11.1 | 28 |
| Korean | 0.5 | 20 | |||
| Polish | 9.5 | 17 | |||
| Russian | 4142 | 198 | 4.77% | 20.2 | 14 |
| Turkish | 2700 | 26 | 0.97% | 4.1 | 14 |
Requires
- python >= 3.6,
- pypy3 >= 5.5 (optional),
- justext >= 3.0 (http://corpus.tools/wiki/Justext),
- chared >= 2.0 (http://corpus.tools/wiki/Chared),
- lxml >= 4.2 (http://lxml.de/),
- openssl >= 1.1,
- pycld2 >= 0.41 (https://pypi.org/project/pycld2/),
- pyre2 >= 0.2.23 (https://github.com/andreasvc/pyre2),
- text processing tools (if binary format conversion is on):
- pdftotext (from poppler-utils),
- ps2ascii (from ghostscript-core),
- antiword (from antiword + perl-Time-HiRes),
- odfpy,
- nice (coreutils) (optional),
- ionice (util-linux) (optional),
- gzip (optional).
Runs in Linux, tested in Fedora and Ubuntu. Minimum hardware configuration (very small crawls):
- 4 core CPU,
- 8 GB system memory,
- some storage space,
- broadband internet connection.
Recommended hardware configuration (crawling ~30 bn words of English text):
- 8-32 core CPU (the more CPUs the faster the processing of crawled data),
- 32-512 GB system memory
(the more RAM the more domains kept in memory and thus more webs visited),
- lots of storage space,
- connection to an internet backbone line.
Includes
A robot exclusion rules parser for Python (v. 1.6.2)
- by Philip Semanchuk, BSD Licence
- see util/robotparser.py
Language detection using character trigrams
- by Douglas Bagnall, Python Software Foundation Licence
- see util/trigrams.py
docx2txt
- by Sandeep Kumar, GNU GPL 3+
- see util/doc2txt.pl
Installation
- unpack: tar -xJvf spiderling-src-*.tar.xz,
- install required tools, see install_rpm.sh for rpm based systems
- check importing the following dependences by pypy3/python3: python3 -c 'import justext.core, chared.detector, ssl, lxml, re2, pycld2' pypy3 -c 'import ssl; from ssl import PROTOCOL_TLS'
- make sure the crawler can write to config.RUN_DIR and config.PIPE_DIR.
Settings -- edit util/config.py
- !!!IMPORTANT!!! Set AGENT, AGENT_URL, USER_AGENT;
- set MAX_RUN_TIME to specify max crawling time in seconds;
- set DOC_PROCESSOR_COUNT to (partially) control CPU usage;
- set MAX_OPEN_CONNS, IP_CONN_INTERVAL, HOST_CONN_INTERVAL;
- raise ulimit -n accoring to MAX_OPEN_CONNS;
- then increase MAX_OPEN_CONNS and OPEN_AT_ONCE;
- configure language and TLD dependent settings.
Language models for all recognised languages
- Plaintext in util/lang_samples/,
e.g. put plaintexts from several dozens of nice web documents and Wikipedia articels, manually checked, in util/lang_samples/{Czech,Slovak,English};
- jusText wordlists in util/justext_wordlists/,
e.g. use the Justext default or 2000 most frequent manually cleaned words, one per line, in util/justext_wordlists/{Czech,Slovak,English};
- chared model in util/chared_models/,
e.g. copy the default chared models {czech,slovak,english}.edm to util/chared_models/{Czech,Slovak,English}
See default English resources in the respective directories.
Usage
See ./spiderling.py -h.
It is recommended to run the crawler in screen.
Example:
screen -S crawling ./spiderling.py < seed_urls &> run/out &
Files created by the crawler in run/:
- *.log.* .. log & debug files,
- arc/*.arc.gz .. gzipped arc files (raw http responses),
- prevert/*.prevert_d .. preverticals with duplicate documents,
- prevert/duplicate_ids .. files duplicate document IDs,
- ignored/* .. ignored URLs (binary files (pdf, ps, doc, docx) which were
not processed and urls not passing the domain blacklist or the TLD filter),
- save/* .. savepoints that can be used for a new run,
- other directories can be erased after stopping the crawler.
To remove duplicate documents from preverticals, run
for pdup in run/prevert/*.prevert_d
do
p=`echo $pdup | sed -r 's,prevert_d$,prevert,'`
pypy3 util/remove_duplicates.py run/prevert/duplicate_ids < $pdup > p
done
Files run/prevert/*.prevert are the final output.
Onion (http://corpus.tools/wiki/Onion) is recommended to remove near-duplicate paragraphs of text.
To stop the crawler before MAX_RUN_TIME, send SIGTERM to the main process (pypy/python spiderling.py). Example:
ps aux | grep 'spiderling\.py' #find the PID of the main process kill -s SIGTERM <PID>
To re-process arc files with current process.py and util/config.py, run
for arcf in run/arc/*.arc.gz
do
p=`echo $arcf | sed -r 's,run/arc/([0-9]+)\.arc\.gz$,\1.prevert_re_d,'`
zcat $arcf | pypy3 reprocess.py > $p
done
To re-start crawling from the last saved state:
mv -iv run old #rename the old `run' directory
mkdir run
for d in docmeta dompath domrobot domsleep robots
do
ln -s ../old/$d/ run/$d
#make the new run continue from the previous state by symlinking old data
done
screen -r crawling
./spiderling.py \
--state-files=old/save/domains_T,old/save/raw_hashes_T,old/save/txt_hashes_T \
--old-tuples < old/url/urls_waiting &> run/out &
(Assuming T is the timestamp of the last save, e.g. 20190616151500.)
Performance tips
- Start with thousands of seed URLs. Give more URLs per domain. It is possible to start with tens of millions of seed URLs. If you need to start with a small number of seed URLs, set VERY_SMALL_START = True in util/config.py.
- Using PyPy reduces CPU cost and may cost more RAM.
- Set TLD_WHITELIST_RE to avoid crawling domains not in the target language (it takes some resources to detect it otherwise).
- Set LOG_LEVEL to debug and set INFO_PERIOD to check the debug output in *.log.crawl and *.log.eval to see where the bottleneck is, modify the settings accordingly, e.g. add doc processors if the doc queue is always full.
Known bugs
- Domain distances should be made part of document metadata instead of storing them in a separate file. It will be resolved in the next version.
- Processing binary files (pdf, ps, doc, docx) is disabled by default since it was not tested and may slow processing significantly. Also, the quality of the text output of these converters may suffer from various problems: headers, footers, lines breaked by hyphenated words, etc.
- Compressed connections are not accepted/processed. Some servers might be discouraged from sending an uncompressed response (not tested).
- Some advanced features of robots.txt are not observed, e.g. Crawl-delay. It would require major changes in the design of the download scheduler. A warning is emitted when the crawl delay < config.HOST_CONN_INTERVAL.
Support
There is no guarantee of support. (The author may help you a bit in his free time.) Please note the tool is distributed as is, it may not work under your conditions.
Acknowledgements
The author would like to express many thanks to Jan Pomikálek, Pavel Rychlý and Miloš Jakubíček for guidance, key design advice and help with debugging. Thanks also to Vlado Benko and Nikola Ljubešić for ideas for improvement.
This software is developed at the Natural Language Processing Centre of Masaryk University in Brno, Czech Republic in cooperation with Lexical Computing, corpus tool company.
This work was partly supported by the Ministry of Education of CR within the LINDAT-Clarin project LM2015071. This work was partly supported by the Norwegian Financial Mechanism 2009–2014 and the Ministry of Education, Youth and Sports under Project Contract no. MSMT-28477/2014 within the HaBiT Project 7F14047.
Contact
'zc.inum.if@2mohcusx'[::-1]
Licence
This software is the result of project LM2010013 (LINDAT-Clarin - Vybudování a provoz českého uzlu pan-evropské infrastruktury pro výzkum). This result is consistent with the expected objectives of the project. The owner of the result is Masaryk University, a public university, ID: 00216224. Masaryk University allows other companies and individuals to use this software free of charge and without territorial restrictions under the terms of the GPL license.
This permission is granted for the duration of property rights.
This software is not subject to special information treatment according to Act No. 412/2005 Coll., as amended. In case that a person who will use the software under this license offer violates the license terms, the permission to use the software terminates.
Changelog
Changelog 2.0 → 2.1 → 2.2
Language detection:
- CLD2 is used together with the simple character trigram model at the document level now. CLD2 is more accurate and it is able to identify languages that the old model does not know. The old model is more permissive but introduces other language texts that have to be filtered later. CLD2 => precision, simple trigrams => recall.
- Language detection at the paragraph level was removed since a paragraph was too short for reliable predictions.
- Lowercase and trim all strings for the trigram langid.
Performance improvements:
- Gzip compression of files to save space where performance is not crucial (i.e. in document processors, not in the downloader).
- Split the ARC output to 100 GB parts, split the prevertical output to 10 GB parts to allow post-processing of closed parts even before the crawl is done.
- When the document processors are overloaded, a limited number of documents from each domain is processed from a single wpage file (the rest is postponed) so for all domains there is some data getting steadily from processors to the scheduler not to stop crawling domains because of their perceived inactivity caused by overloaded processors, not by depleted domains.
- Ignore edit pages and diff pages which usually contribute no new texts.
- Limit the size of wpage processing queue not to eat up the memory by big crawls: config.MAX_WPAGE_PROCESSING_COUNT.
Bugfixes:
- Write the rest of duplicate doc IDs after termination.
- Fixed a missing primary multilanguage flag in re-processing code.
Other:
- More domains in the default blacklist.
- Pad prevertical file names to two digits to ease their processing and sorting.
- Allow keeping arc output when re-processing wpage data.
- Use --saved-hashes to initialize the hashes of raw data and plaintext by savepoint values when re-processing wpage data.
- url/download_queue added to the restart command line to load a saved downloader queue.
Changelog 1.3 → 2.0
Major bugfixes
- ignored redirection to path + "/" fixed
- binary files discard fixed (text extraction from pdf, doc,... works now)
Major updates
- multilingual website support (see util/config.py)
- keeping near-good or even bad paragraphs allowed
Minor updates
- machine translation filter (based on some known MT identifiers in HTML)
- extract text from ODF format (.odt files)
- get file type from Content-Type from the HTTP header
- add HTTP Last-Modified date to prevertical
- Justext classification added to paragraph attributes
Changelog 1.1 → 1.3
- decode IDNA hostnames in prevertical
- adding URLs to download on-the-fly enabled
- bugfixes
Changelog 1.0 → 1.1
- Important bug fix: Store the best extracted paragraph data in process.py. (Fixes a bug that caused Chared model for the last tested language rather than the best best tested language was used for character decoding. E.g. koi8-r encoding could have been assumed for Czech documents in some cases and when the last language in config.LANGUAGES was Russian.) Also, chared encodings were renamed to canonical encoding names.
- Encoding detection simplified, Chared is preferred now
- Session id (and similar strings) removed from paths in domains to prevent downloading the same content again
- Path scheduling priority by path length
- Memory consumption improvements
- More robust error handling, e.g. socket errors in crawl.py updated to OSError
- reprocess.py can work with wpage files too
- config.py: some default values changed for better performance (e.g. increasing the maximum open connections limit helps a lot), added a switch for the case of starting with a small count of seed URLs, tidied up
- Debug logging of memory size of data structures
Changelog 0.95 → 1.0
- Python 3.6+ compatible
- Domain scheduling priority by domain distance and hostname length
- Bug fixes: domain distance, domain loading, Chared returns "utf_8" instead of "utf-8", '<', '>' and "'" in doc.title/doc.url, robots.txt redirected from http to https, missing content-type and more
- More robust handling of some issues
- Less used features such as state file loading and data reprocessing better explained
- Global domain blacklist added
- English models and sample added
- Program run examples in README
Changelog 0.82 → 0.95
- Interprocess communication rewritten to files
- Write URLs that cannot be downloaded soon into a "wpage" file -- speeds up the downloader
- New reprocess.py allowing reprocessing of arc files
- Https hosts separated from http hosts with the same hostname
- Many features, e.g. redirections, made in a more robust way
- More options exposed to allow configuration, more logging and debug info
- Big/small crawling profiles setting multiple variables in config
- Performance and memory saving improvements
- Bugfixes: chunked HTTP, XML parsing, double quotes in URL, HTTP redirection to the same URL, SSL layer not ready and more
Changelog 0.82 → 0.85
- Mistakenly ignored links fixed in process.py
- the bug caused not crawling a significant part of the web
- Multithreading issues fixed (possible race conditions in shared memory)
- delegated classes for explicit locking of all shared objects (esp. DomainQueue)
- Deadlock observed in the case of a large scale crawling fixed (up to v. 0.84)
- Several Domain and DomainQueue methods were rewritten for bulk operations (e.g. adding all paths into a single domain together) to improve performance
- External Robot exclusion protocol module rewritten
- unused code removed
- performance issues and bug in re fixed -- requires re2 now
- Chunked HTTP reponse and URL handling methods rewritten (performance, bugs)
- Justext configuration
- more permissive setting than the justext default
- configurable in util/config.py
Changelog 0.81 → 0.82
- Crawling multiple languages improved
- recognise multiple languages, accept a subset of these languages
Changelog 0.77 → 0.81
- Improvements proposed by Vlado Benko or Nikola Ljubešić:
- escape square brackets and backslash in url
- doc attributes: timestamp with hours, IP address, meta/chared encoding
- doc id added to arc output
- MAX_DOCS_CLEANED limit per domain
- create the temp dir if needed
- Support for processing doc/docx/ps/pdf (not working well yet, URLs of documents are saved to a separate file for manual download and processing)
- Crawling multiple languages (Inspired by Nikola's contribution) (not tested yet)
- Stop crawling by sending SIGTERM to the main process
- Domain distances (distance of web domains from seed web domains, will be used in scheduling in the future)
- Config values tweaked
- MAX_URL_QUEUE, MAX_URL_SELECT greatly increased
- better spread of domains in the crawling queue => faster crawling
- Python --> PyPy
- scheduler and crawler processes dynamically compiled by pypy
- saves approx. 1/4 RAM
- better CPU effectivity not so visible (waiting for host/IP timeouts, waiting for doc processors)
- process.py requires lxml which does not work with pypy (will be replaced by lxml-cffi in the future)
- Readme updated (more information, known bugs)
- Bug fixes
Attachments (1)
- crawled_sizes_2019.png (208.1 KB ) - added by 5 years ago.
{kind=link}
Download all attachments as: .zip